Die Herausforderung
Man habe ein "Bad Storage". Die Festplatte liefere also andere Daten als man ursprünglich geschrieben hat.
Die meisten für uns relevanten Dateisysteme (darunter ext4, XFS, btrfs, ZFS) sind mittlerweile so weit, dass sie für ihre eigenen Metadaten irgendeine Form von Checksumme haben. Flippt also im ext4-Journal ein Bit, dann sollte ext4 das mitbekommen.
Die traditionellen Platzhirsche ext4 und XFS haben aber derzeit noch keine Checksummen für die tatsächlichen Nutzdaten. Nur weil man ein Dateisystem mounten und davon lesen kann, heißt das also noch lange nicht, dass man die richtigen Daten bekommt.
Dieser Blog-Artikel beschäftigt sich damit, wie Dateisysteme damit umgehen, wenn das Storage-Device in Nutzdaten auf einmal irgend etwas zurückgibt, was dort ursprünglich gar nicht geschrieben wurde. Die Betonung liegt hier auf "etwas anderes". Wenn das Storage einen definitiven I/O-Error liefert, dann ist das nochmal eine andere Geschichte, über die Dan Luu schon vor einiger Zeit einen wunderbaren Artikel geschrieben hat.
Disclaimer: Nein, die Daten sind nicht "korrupt" und sie lassen sich bestechen. Wem eine bessere Übersetzung für den Begriff "Data Corruption" einfällt, kann unter dem Beitrag gerne einen Kommentar abgeben. 😀
Warum ist das Thema relevant?
Über Privatsysteme möchte ich gar nicht reden. Hier sind gar keine Methoden verbreitet, um überhaupt feststellen oder messen zu können, wie viele Daten kaputtgehen oder wie oft das während der allgemeinen Lebensdauer einer SSD überhaupt passiert.
"Professionelle" Systeme sind jedoch meistens mit Hardware ausgestattet, die Fehler erkennen und melden soll. Das ist die Standardbegründung: "Es ist viel zu langsam, Checksummen im Dateisystem zu behandeln; das muss Hardware erledigen!"
Aber es ist nicht einmal die Hardware, die kaputtgehen muss. Wir haben letztens folgendes Szenario erlebt: Ein Ausfall, Storage war "irgendwie" in Mitleidenschaft gezogen worden; Schuld ist wohl ein Software-Bug gewesen. Eine Reihe von VMs war betroffen - und hier hatten wir nun deren virtuelle Festplatten, von denen manchen noch gingen, während andere sich nicht booten ließen.
Der Punkt ist: Nur, weil ein System bootet und ein anderes nicht, heißt das noch lange nicht, dass das bootende System "in Ordnung" ist. Vielleicht ist das System eben doch kaputt, aber an Stellen, die wir bisher noch nicht untersucht haben. Allein für solche Fälle – die jederzeit auftreten können – braucht es geeignete Werkzeuge.
Beim unserem Ausfall habe ich ein möglicherweise betroffenes ZFS-Dateisystem mounten und die Datenbank von dort auf ein neues Storage kopieren können. Dank Checksummen kann ich mir sicher sein, dass das korrekte Daten sind. Und das ist enorm viel wert.
ext4 und XFS
Man erstelle eine virtuelle Maschine mit einer virtuellen Festplatte. Die Daten liegen also als Datei auf der echten Festplatte und diese Datei kann man nach Belieben verändern – auch während die VM läuft.
Fangen wir mit ext4 an:
root@ubuntu1604lts:~# mkfs.ext4 /dev/vdb
mke2fs 1.42.13 (17-May-2015)
Creating filesystem with 524288 4k blocks and 131072 inodes
Filesystem UUID: dc922715-4592-4235-a8ce-328598db12bd
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
root@ubuntu1604lts:~# mkdir /ext4
root@ubuntu1604lts:~# mount /dev/vdb /ext4
root@ubuntu1604lts:~# cp data /ext4; sync
root@ubuntu1604lts:~# md5sum data
003267328702f8fa5ea3880f15b8d175 data
Die manuell erzeugte Checksumme 003267328702f8fa5ea3880f15b8d175 kann man sich nun merken. Sobald wir hier ein anderes Ergebnis sehen, haben wir korrupte Daten gelesen.
Mein Disk-Image kann ich dann auf dem Host mit bvi (Achtung, cooles Programm, das aber bei Dateien größer als 2 GB schlappmacht und die Datei beschädigt...) öffnen und nach einem Muster suchen, von dem ich weiß, dass es in der Datei data auftaucht:
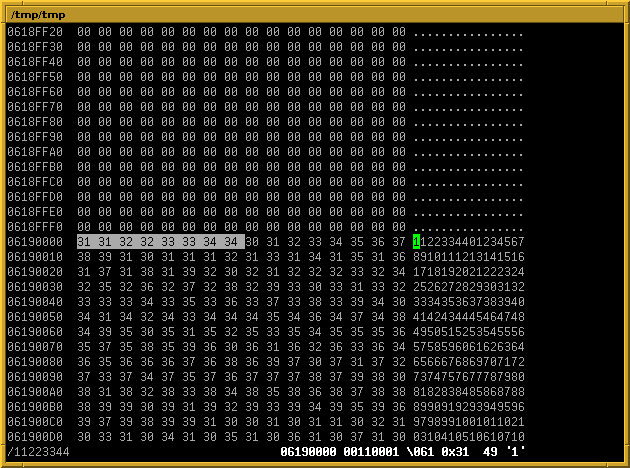
Ich ersetze nun am Anfang 11 durch 21 und speichere. Innerhalb der VM ist es jetzt wichtig, die I/O-Caches zu leeren. Dadurch ist der Kernel gezwungen, die Blöcke tatsächlich neu von der "Festplatte" zu lesen, statt einfach das (weiterhin korrekte) Ergebnis möglicherweise aus dem Cache zu liefern:
root@ubuntu1604lts:~# echo 3 >/proc/sys/vm/drop_caches root@ubuntu1604lts:~# md5sum /ext4/data 852e3c18d920f7b646ebf46dd6a2fc83 /ext4/data
Meine Datei ist also kaputt. Niemand sagt etwas. Kein I/O-Error im dmesg. Das war zu erwarten, weil ext4 uns vor solchen Situationen nicht schützt.
Mit XFS sieht das Ergebnis genauso aus:
root@ubuntu1604lts:~# mkfs.xfs /dev/vdb
meta-data=/dev/vdb isize=512 agcount=4, agsize=131072 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0
data = bsize=4096 blocks=524288, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
root@ubuntu1604lts:~# mkdir /xfs
root@ubuntu1604lts:~# mount /dev/vdb /xfs
root@ubuntu1604lts:~# cp data /xfs; sync
... Disk-Image kaputtmachen ...
root@ubuntu1604lts:~# echo 3 >/proc/sys/vm/drop_caches
root@ubuntu1604lts:~# md5sum /xfs/data
852e3c18d920f7b646ebf46dd6a2fc83 /xfs/data
btrfs
btrfs hat Prüfsummen für Metadaten und Daten. Hier erwarte ich also, dass der Fehler prominent erkannt wird. Und nicht nur das: Ich hätte gerne beim Lesen der Datei einen I/O-Error. Ich will nicht, dass Userspace-Programme mit falschen Daten arbeiten.
Also noch einmal - Dateisystem erstellen und Datei schreiben:
root@ubuntu1604lts:~# mkfs.btrfs /dev/vdb
btrfs-progs v4.4
See http://btrfs.wiki.kernel.org for more information.
Label: (null)
UUID: fc670952-b330-4978-8aa3-79e97f1dca32
Node size: 16384
Sector size: 4096
Filesystem size: 2.00GiB
Block group profiles:
Data: single 8.00MiB
Metadata: DUP 110.38MiB
System: DUP 12.00MiB
SSD detected: no
Incompat features: extref, skinny-metadata
Number of devices: 1
Devices:
ID SIZE PATH
1 2.00GiB /dev/vdb
root@ubuntu1604lts:~# mkdir /btrfs
root@ubuntu1604lts:~# mount /dev/vdb /btrfs
root@ubuntu1604lts:~# cp data /btrfs; sync
Das Ergebnis:
root@ubuntu1604lts:~# echo 3 >/proc/sys/vm/drop_caches root@ubuntu1604lts:~# md5sum /btrfs/data md5sum: /btrfs/data: Input/output error
Das ist gut. Das Programm bekommt einen Fehler gemeldet. Durch Scrubbing erhalten wir mehr Informationen:
root@ubuntu1604lts:~# btrfs scrub start -Bd /btrfs
scrub device /dev/vdb (id 1) done
scrub started at Sat Aug 5 10:10:52 2017 and finished after 00:00:00
total bytes scrubbed: 69.94MiB with 1 errors
error details: csum=1
corrected errors: 0, uncorrectable errors: 1, unverified errors: 0
ERROR: there are uncorrectable errors
root@ubuntu1604lts:~# dmesg | tail
[ 210.473959] BTRFS warning (device vdb): checksum error at logical 136708096 on dev /dev/vdb, sector 493056, root 5, inode 257, offset 0, length 4096, links 1 (path: data)
Versteckt in dmesg ist also auch der betroffene Pfad zu sehen. Dieses Verhalten ist genau so, wie wir es uns wünschen. 🙂 Der betroffene Pfad könnte zwar prominenter gemeldet werden, aber gut.
Jetzt kommt das "aber". Während meiner Tests habe ich auch einmal das hier gesehen:
root@ubuntu1604lts:~# echo 3 >/proc/sys/vm/drop_caches root@ubuntu1604lts:~# md5sum /btrfs/data 8960e10751b08e8d3e1d88138955601f /btrfs/data
Unterschiedlicher Inhalt, kein Fehler. In dmesg sah ich nur dies:
[ 117.724576] BTRFS info (device vdb): no csum found for inode 257 start 16605184
Aktives Scrubbing hat dann Folgendes gemeldet:
root@ubuntu1604lts:~# btrfs scrub start -Bd /btrfs
ERROR: scrubbing /btrfs failed for device id 1: ret=-1, errno=5 (Input/output error)
scrub device /dev/vdb (id 1) canceled
scrub started at Sat Aug 5 09:48:30 2017 and was aborted after 00:00:00
total bytes scrubbed: 0.00B with 2 errors
error details: super=2
corrected errors: 0, uncorrectable errors: 0, unverified errors: 0
Was hier nun kaputt ist, wurde mir nicht gesagt. Das finde ich etwas bedenklich. Offenbar habe ich einen Ausnahmefall getriggert, in dem btrfs dann falsche Daten an den Userspace geschickt hat. Reproduzieren konnte ich das zwar nicht, aber ein schlechtes Bauchgefühl hinterlässt es trotzdem.
ZFS
Weil meine Ubuntu-VM schneller bootet als die mit FreeBSD, habe ich zum Testen ZFS on Linux in der Version 0.6.5.6 von Ubuntu 16.04 benutzt.
root@ubuntu1604lts:~# cp data /tank root@ubuntu1604lts:~# sync ... Disk-Image kaputtmachen ... root@ubuntu1604lts:~# echo 3 >/proc/sys/vm/drop_caches root@ubuntu1604lts:~# md5sum /tank/data md5sum: /tank/data: Input/output error
Wunderbar. Statt den Userspace mit Garbage-Daten weiterarbeiten zu lassen, wird ein Fehler gemeldet.
Läuft man in die Situation, irgendwo I/O-Fehler zu bekommen, dann kann man sich auch bei ZFS anzeigen lassen, was denn da kaputt ist:
root@ubuntu1604lts:~# zpool status -v
pool: tank
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://zfsonlinux.org/msg/ZFS-8000-8A
scan: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 1
vdb ONLINE 0 0 2
errors: Permanent errors have been detected in the following files:
/tank/data
Die Datei /tank/data wird als defekt gemeldet. Es ist sicher Geschmackssache, die Ausgabe gefällt mir aber besser als bei btrfs.
Bei ZFS gibt es dann auch einen Scrub-Mechanismus, um alle Daten zu testen und somit Fehler aufzudecken, denen man nicht zufällig begegnet ist:
root@ubuntu1604lts:~# zpool scrub tank
root@ubuntu1604lts:~# zpool status -v
pool: tank
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://zfsonlinux.org/msg/ZFS-8000-8A
scan: scrub repaired 0 in 0h0m with 2 errors on Sat Aug 5 09:57:55 2017
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 3
vdb ONLINE 0 0 6
errors: Permanent errors have been detected in the following files:
/tank/foo
/tank/data
Die Datei /tank/foo hatte ich in der Zwischenzeit noch kaputtgemacht.
(Zwischen-)Fazit
ext4 und XFS: Hat man hier keine zusätzliche Absicherung im Userspace, bekommt man keine Fehler dieser Art mit. Es gibt immerhin Ansätze wie bitrot, das Checksummen von normalen Dateien in normalen Dateien speichert. Das können wir dann regelmäßig laufenlassen und erwischen zumindest einen Teil. Bei Distributionen, die auf Debian basieren, kann debsums eine weitere Alternative darstellen. Aber natürlich hat man die Absicherung nicht bei jedem Lesevorgang - und dies ist etwas, was ich mir wünschen würde. Gerne verzichte ich dafür auf Performance.
btrfs ist schon ein guter Schritt nach vorne. Dass es mir kurz gelungen ist, btrfs Käse zurückliefern zu lassen, ist schade. Ich muss natürlich hinzufügen, dass das Ubuntu 16.04 mit Kernel 4.4 war und wir aktuell schon bei 4.12 sind. Gut möglich, dass das mittlerweile gefixt ist. Da sich das Fehlverhalten auch bei 4.4 nicht eindeutig reproduzieren ließ, habe ich es gar nicht erst mit 4.12 getestet.
ZFS verhielt sich in meinem Test vorbildlich. Wäre da nicht das mit der Lizenz und der ganze klobige Solaris-Unterbau...
Ausblick
Ende 2016 wurde mehr oder weniger angekündigt, dass XFS bald Data-Scrubbing beherrschen könnte:
This reverse mapping infrastructure is the building block of several upcoming features - reflink, copy-on-write data, dedupe, online metadata and data scrubbing, highly accurate bad sector/data loss reporting to users, and significantly improved reconstruction of damaged and corrupted filesystems. There's a lot of new stuff coming along in the next couple of cycles, and it all builds in the rmap infrastructure.
Spannend ist an dieser Stelle natürlich auch die Erwähnung von CoW und Dedup. Da das aber ganz schön viel Arbeit ist, wird es noch dauern.
Bei ext4 beziehungsweise dem Device-Mapper gab es auch schon 2014 Überlegungen, Data-Checksums zu bauen. Wetten würde ich hierauf aber nicht.

Mehr über die Creative-Commons-Lizenz erfahren
