Der Erfolg eines Unternehmens gründet auf erfolgreichen Teams, und gute Teams sind bestrebt, ständig nach Verbesserungsmöglichkeiten ihrer Methoden und Prozesse zu suchen, um noch bessere Ergebnisse liefern zu können. Eine kontinuierliche Verbesserung braucht Reflexion der eigenen Arbeit und möglichst belastbare Informationen.
Die Daten-Pipeline in Jira gibt uns hilfreiche Werkzeuge an die Hand, um die Nutzung des Systems besser zu verstehen und zu optimieren. Sie generiert nicht einfach Daten, sondern sie bietet die Möglichkeit, aus Jira aktionable Einsichten und Trends abzuleiten, die konkrete Handlungsoptionen eröffnen können. In einem früheren Blog-Beitrag haben wir die Vorteile der Daten-Pipeline bereits zusammengefasst. Heute wollen wir uns mal einigen konkreten Funktionen widmen.
Das DevOps-Dashboard mit seinen zentralen Informationen
Der Startpunkt ist ein DevOps-Dashboard, das für Tableau und Microsoft PowerBI verfügbar ist und auf dem wir konkrete Informationen zur Arbeit und zur Prozessgesundheit unseres Teams einsehen können. Dieses Dashboard lässt sich an unsere eigenen Datenquellen anschließen oder als Ausgangspunkt für die Erstellung individueller Dashboards nutzen. Es bietet uns die folgenden Details:
- Projektzusammenfassung: Sie listet die Projekte auf dem Dashboard auf und zeigt die Ressourcen, die in ihnen jeweils gebunden sind. Die Liste fungiert auch als Filter, sodass wir tiefer einsteigen können, beispielsweise um die Daten eines bestimmten Projekts einzusehen und um es mit der Gesamtheit der Projekte zu vergleichen.
- Allokationsmetriken: Sie zeigen für jedes Projekt den prozentualen Anteil der Ressourcen, die wöchentlich in die Umsetzung einfließen (gemessen in abgeschlossenen Vorgängen durch Teammitglieder).
- Qualitätsmetriken: Diese Diagramme gewähren Einblicke in die Qualität, die Responsivität, die Produktivität und die Vorhersagbarkeit für alle Projekte oder ein ausgewähltes Projekt.
- Qualitätszusammenfassung: Sie zeigt aggregierte Werte für jede der vier Qualitätsmetriken nach Projekten, um Ausreißer oder systemische Probleme zu identifizieren.
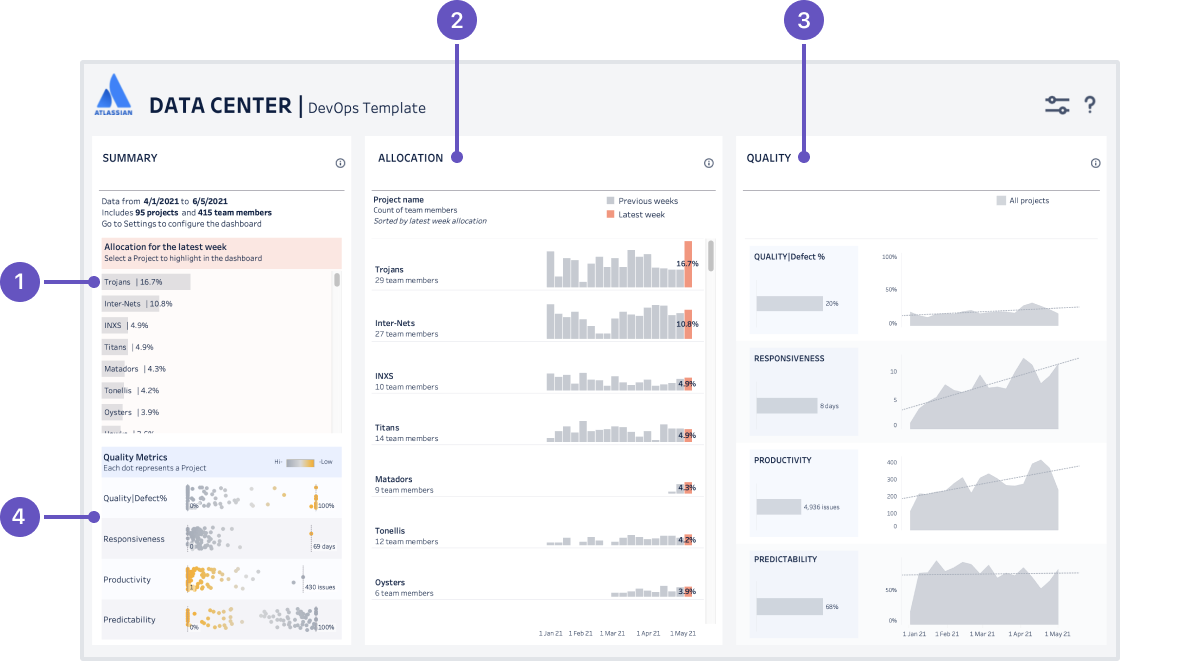
Das Dashboard ist konfigurierbar. Wenn wir uns hier befinden, können wir auswählen, ob wir die Daten nach Projekt oder Projektkategorie aggregieren wollen. Außerdem haben wir die Möglichkeit, Parameter wie die Zeitspanne sowie die Projekte, Leute und Vorgangstypen, die eingeschlossen werden sollen, zu konfigurieren.
In der Atlassian-Doku gibt es ausführliche Details über das Dashboard und die Metriken: Make the most of the Data Pipeline with the DevOps dashboard.
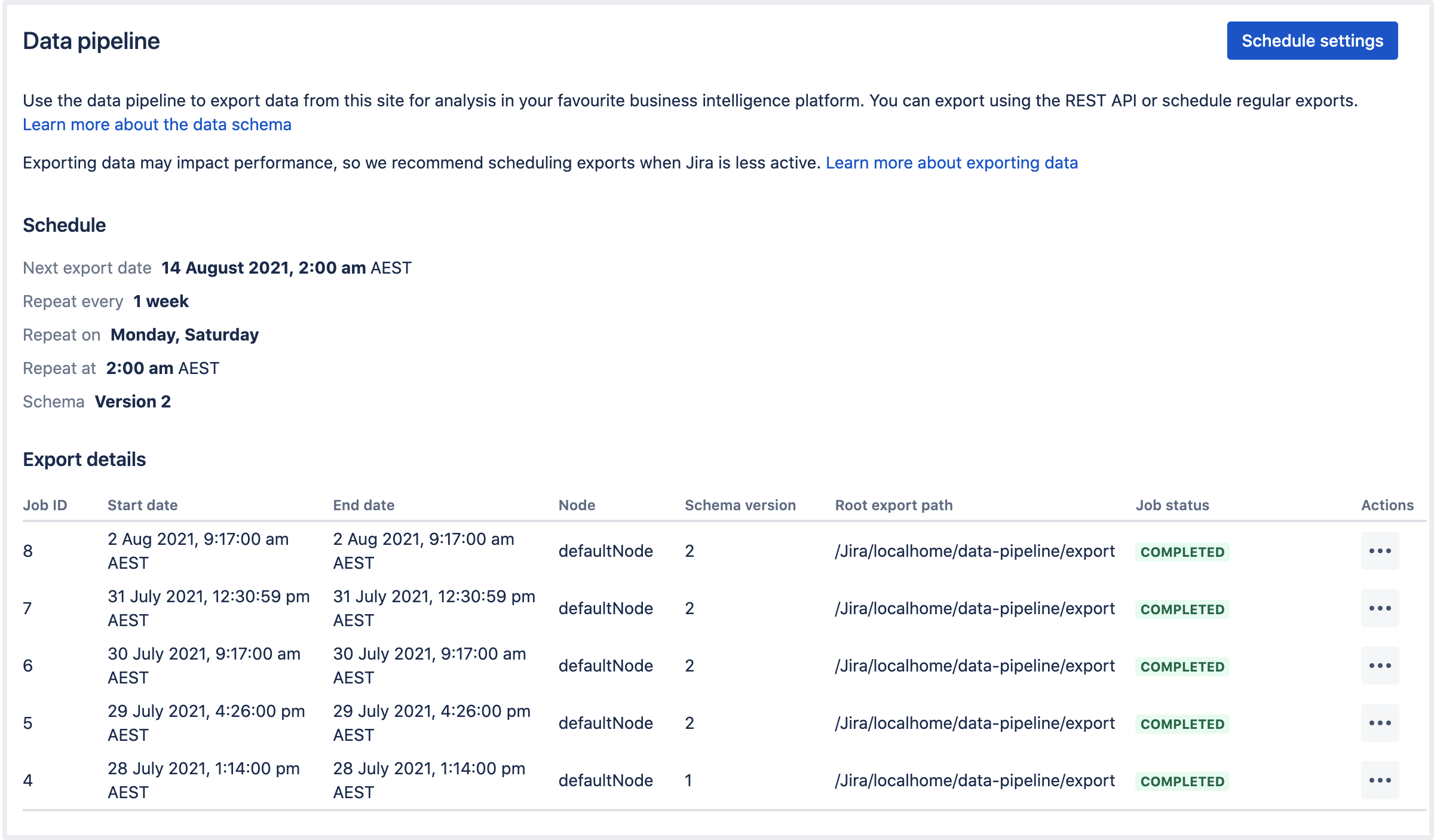
Regelmäßige Exporte planen
Nachdem wir ein Dashboard erstellt und festgelegt haben, wie Daten aufgenommen und transformiert werden sollen, müssen wir im nächsten Schritt entscheiden, in welchen Zeitintervallen regelmäßige Aktualisierungen erfolgen sollen.
Damit das so einfach wie möglich und vor allem lückenlos geschieht, besteht die Option, in der Administration der Daten-Pipeline regelmäßige automatisierte Exporte zu planen. Wie häufig das passieren soll, ist uns überlassen. Im Administrationsbildschirm finden wir Details zu den letzten Exporten und können auch direkt sehen, wann der nächste Export eingeplant ist.
Viele Datenpunkte für ein Gesamtbild
Jira ist eine Schatztruhe mit nützlichen Daten, die nur darauf wartet, gehoben zu werden, um Reports und Visualisierungen zur Nutzeraktivität zu generieren und die Nutzung des Systems besser zu verstehen, woraus sich dann im individuellen Fall sinnvolle Handlungsempfehlungen ableiten lassen.
Zu den exportierbaren Informationen gehören nicht nur die Projekte und Vorgänge mitsamt ihrer Felder und historischen Daten, sondern auch von Menschen und Apps erstellte Custom Fields. Und mit der jüngsten Version von Jira Data Center (8.19) sind noch einmal weitere Optionen hinzugekommen:
- Nutzerdetails: Die Nutzerdetails werden in eine eigene Datei exportiert. Das erleichtert uns die Cross-Referenzierung von User-IDs mit einem einzelnen Set von Teammitgliedern mit Namen und E-Mail-Adressen. Zudem hilft dieser Ansatz bei der Anonymisierung unserer Daten, da zum Beispiel die Datei mit exportierten Vorgängen nicht mehr die vollen Namen der Leute enthält.
- Vorgangsverknüpfungen: Die Beziehungen zwischen Vorgängen können sehr wichtig sein. Jetzt werden Vorgangsverknüpfungen in eine eigene Datei exportiert, sodass wir anschließend zum Beispiel die Issues identifizieren können, die von anderen dupliziert oder geblockt sind.
- Archivierte Vorgänge: Wir haben außerdem die Möglichkeit, archivierte Vorgänge in unseren Export zu integrieren. Sie sind jeweils mit Archivierungsdatum und dem Initiator der Archivierung versehen.
Ihr Partner für Atlassian Jira
Haben Sie Fragen zu Atlassian Jira? Seibert Media ist Atlassian Platinum Solution Partner. Wir helfen Ihnen bei allen Aspekten rund um eine Einführung und produktive Nutzung von Jira in Ihrem Unternehmen – von der strategischen Beratung über die Lizenzierung bis zur Implementierung, Optimierung und Erweiterung. Melden Sie sich bei uns!
Weiterführende Infos
Ist Jira in Ihren IT- und Entwicklungsteams gefangen?
Die Daten-Pipeline in Atlassian Data Center
Scaled Agile: SAFe in Jira versus SAFe in Jira mit Agile Hive
Agile-Skalierung mit Jira Align: Abhängigkeiten überwinden, Teams auf eine Linie bringen, kontinuierlich Wert ausliefern



