Die sich schnell wandelnden Bedingungen der modernen Welt und aufstrebende Wettbewerber verlangen von Unternehmen schnell gute Entscheidungen, um erfolgreich zu bleiben. Das erfordert wiederum bessere Datenanalyse-Werkzeuge, die stets auch das große Ganze zeigen.
Viele Organisationen entscheiden sich in diesem Zusammenhang für Data-Warehouse-Lösungen wie beispielsweise Amazon Redshift oder Google BigQuery, um ihre Daten zu analysieren. Diese Lösungen bieten eine hohe Skalierbarkeit und flexible Rechenleistung, die schnell auf den aktuellen Bedarf abgestimmt werden kann. Zudem werden sie von diversen Datenanalyse-Tools unterstützt. Das versetzt Unternehmen in die Lage, schnell umfassende Datenanalysen zu erstellen und auch für größte Datenmengen in vertretbarer Zeit informative Auswertungen zu generieren.
Allerdings sind die Unternehmensdaten oft über unterschiedliche Systeme und Anwendungen hinweg verstreut: Ehe man sie analysieren kann, muss man sie erstmal ins Data Warehouse bekommen. Und das ist nur ein Teil des Problems: Um Informationen in richtige Entscheidungen zu konvertieren, müssen die Daten im Data Warehouse so aktuell wie möglich sein.
Ziehen wir mal einen spezifischen Anwendungsfall heran: Wir wollen die Unternehmensdaten aus einem Jira-System analysieren und haben uns für Google BigQuery als Data Warehouse für die Analyse entschieden. Es gibt unterschiedliche Wege, um dieses Szenario zu handhaben: Wir können entweder unsere individuelle Lösung entwickeln oder am Markt nach bestehenden Tools Ausschau halten.
Eine individuelle Lösung auf Basis der Jira-REST-API erstellen
Wenn man eine eigene ETL-Lösung erstellt, sind viele Aspekte zu berücksichtigen - von der Wahl einer Plattform und der zu verwendenden Tools bis zu den Spezifika integrierter Datenquellen. Außerdem muss die Lösung automatisiert sein, damit die Daten synchron sind, ohne dass dabei viel manuelle Arbeit entsteht.
Bei der Umsetzung einer individuellen Integration sollten wir uns als erstes die REST-API von Jira ansehen. Atlassian bietet hierzu eine detaillierte Dokumentation an.
Diese API ermöglicht das Extrahieren von Jira-Daten und die Ausgabe im JSON-Format. Folglich besteht der nächste Schritt darin, ein BigQuery-Schema zu definieren, um Jira-Daten zu speichern und die extrahierten Daten in ein Format zu konvertieren, das in BigQuery importiert werden kann. Danach müssen wir diese Daten in BigQuery laden. Die BigQuery-Dokumentation bietet diverse Wege dafür.
Der letzte Schritt ist schließlich die Automatisierung dieses Prozesses, damit die Daten synchronisiert werden, ohne dass Nutzerinteraktion erforderlich ist.
Dieses Beispiel zeigt: Die Entwicklung einer individuellen Lösung ist eine komplexe Aufgabe. Sie erfordert gewisse Entwicklerkenntnisse und spezifische Werkzeuge. Außerdem muss der Entwickler die APIs der integrierten Quellen studieren und die Lösung für den Fall, dass es Änderungen an den APIs gibt, auf dem neuesten Stand halten.
Aus diesen Gründen besteht die bessere und effektivere Lösung oft darin, ein Drittanbieter-Tool heranzuziehen, dessen Entwickler die anfallenden Aufgaben bereits gelöst haben.
Mit Skyvia in wenigen Minuten Jira-Daten in BigQuery integrieren
Für unser Szenario haben wir Skyvia gewählt, um die Datenreplikation durchzuführen. Skyvia ist eine Cloud-basierte Datenplattform für diverse datenorientierte Aufgaben - beispielsweise Integration, Backup und Verwaltung von Daten. Sie unterstützt alle großen SaaS-Applikationen, Datenbanken und Flat Files. Besonders stark ist Skyvia im Laden von Daten zwischen verschiedenen Quellen - inklusive Jira und BigQuery.
Als Partner sowohl von Jira als auch von BigQuery bietet Skyvia einerseits Werkzeuge für eine schnelle und einfache Datenreplikation von Jira zu BigQuery mit wenig Konfigurationsaufwand (ELT) und andererseits Tools für den erweiterten Datenimport mit mächtigen Transformationen (ETL). Mit Skyvia kann kann die Datenfracht einfach automatisiert werden.
Die Datenreplikation von Jira zu BigQuery ist intuitiv und dauert nur wenige Minuten. Skyvia kann unsere bestehenden Jira-Daten nicht nur in BigQuery laden, sondern diese Daten nach dem initialen Prozess auch automatisch aktuell halten.
Die Replikation in Skyvia konfigurieren
Um die Skyvia-Replikation zu nutzen, müssen wir auf der Website erstmal einen Account anlegen. (Es ist auch ein Login mit Google oder Salesforce möglich.)
In diesem neuen Account können wir direkt damit beginnen, unser Replikations-Package zu zu konfigurieren:
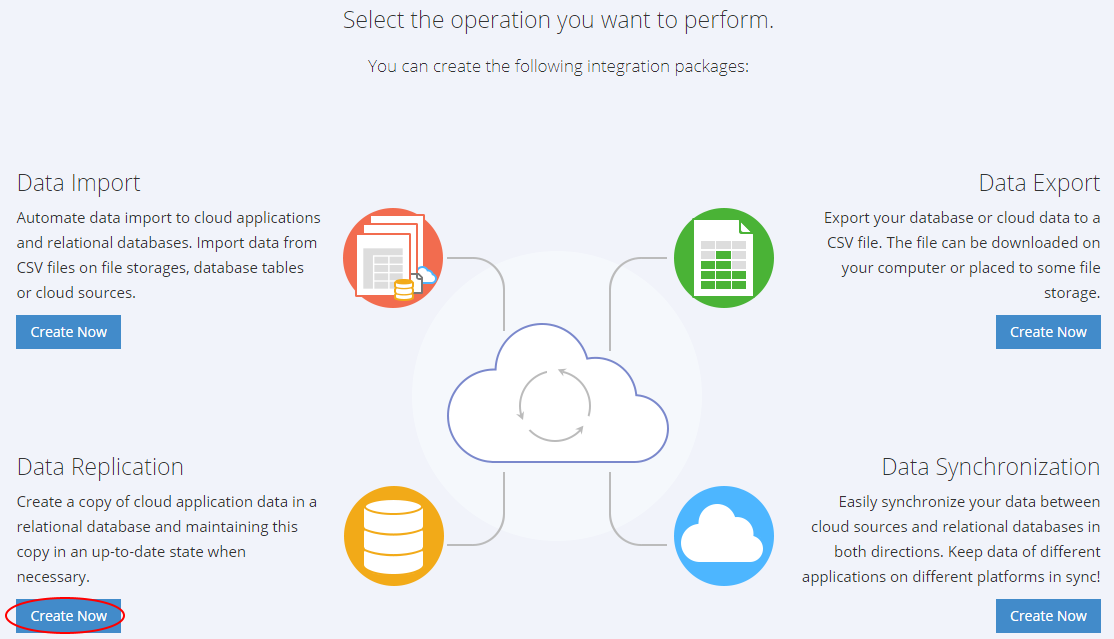
Tatsächlich braucht es nur die folgenden drei Schritte:
1. Zunächst wählen wir die Art der Datenquelle und erstellen die erforderlichen Verbindungen mit dem Jira-Account als Quelle und BigQuery als Ziel.
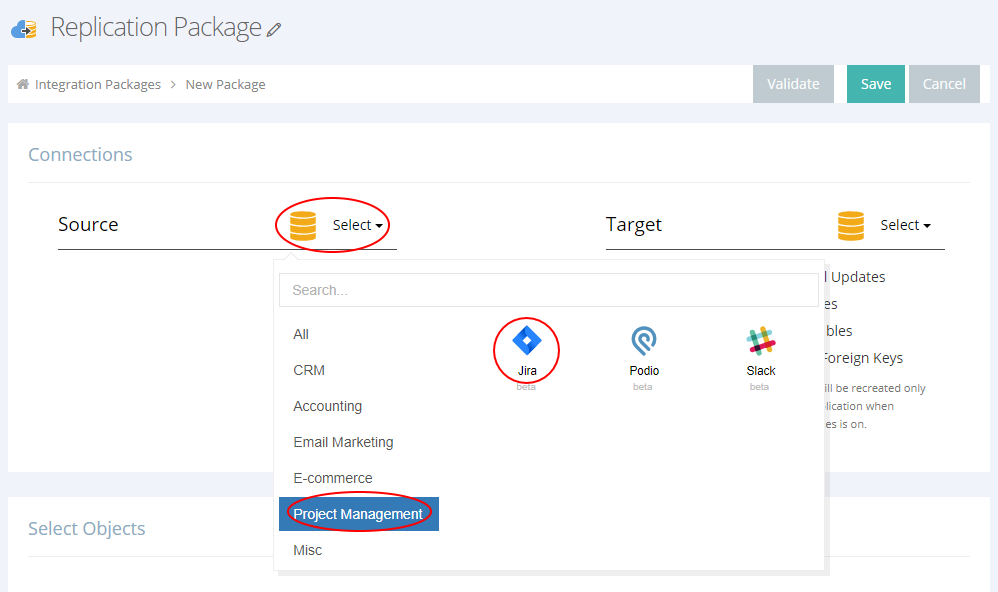
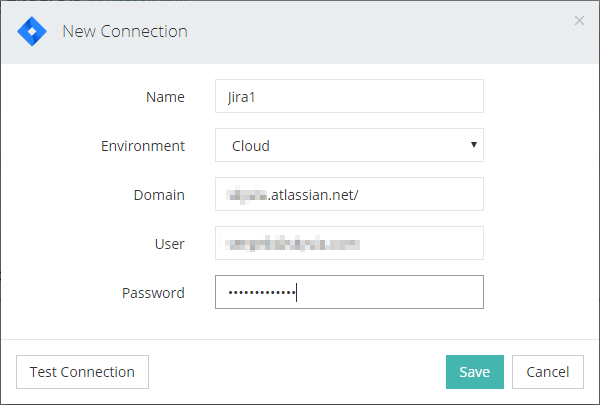
Für die Verbindung mit Jira müssen wir die Domain spezifizieren und einen entsprechenden Nutzernamen mit Passwort bereithalten.
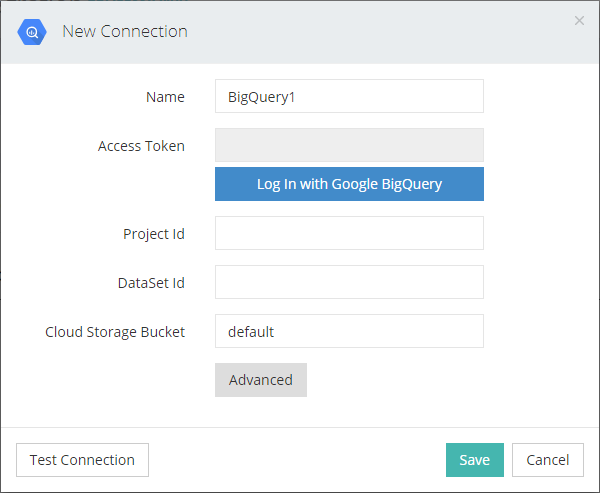
Für die Verknüpfung mit BigQuery loggen wir uns mit Google BigQuery ein und erlauben den Zugriff durch Skyvia. Dann müssen wir die IDs für ein Projekt und ein Datenset angeben, für die wir eine Verbindung einrichten wollen.
2. Anschließend wählen wir aus, welche Daten aus Jira wir replizieren möchten.
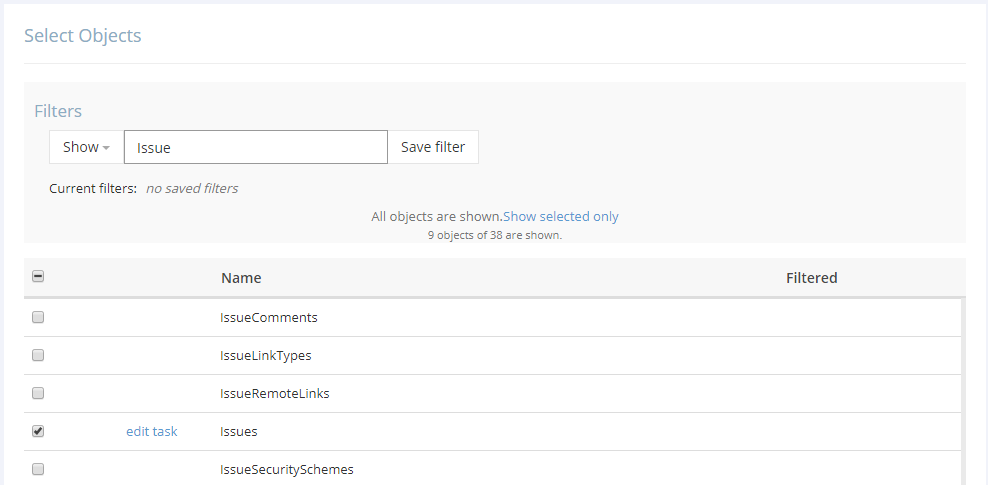
3. Dann kann das Package zur automatischen Ausführung eingeplant werden, sodass die Daten in BigQuery stets aktuell sind. Das war’s.
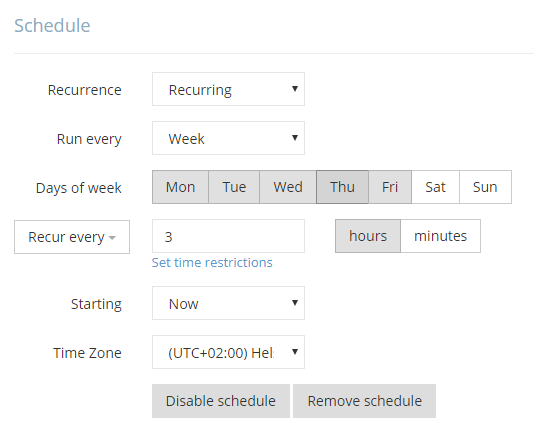
Nachdem wir das Package gespeichert haben, wird es automatisch planmäßig ausgeführt. Die BigQuery-Daten sind damit immer auf dem aktuellen Stand und jederzeit für unsere Datenanalysen oder Reporting-Tools verfügbar, ohne dass wir ihnen manuelle Pflege angedeihen lassen müssen.



